Fundamental of Keras/TensorFlow
Bài viết này giới thiệu một cách cơ bản về các khái niệm và cách giải quyết một bài toán Neural Network cơ bản với Keras/Tensorflow.
Mạng Neural là gì
- Gồm những layers: input layer, hidden layer, output layer
- Đưa dữ liệu vào input layer và lấy dữ liệu ra ở output layer
-
Mỗi layer gồm những unit ⇒ tùy vào kiến trúc mạng, từng bài toán sẽ quy định số unit trong 1 layer
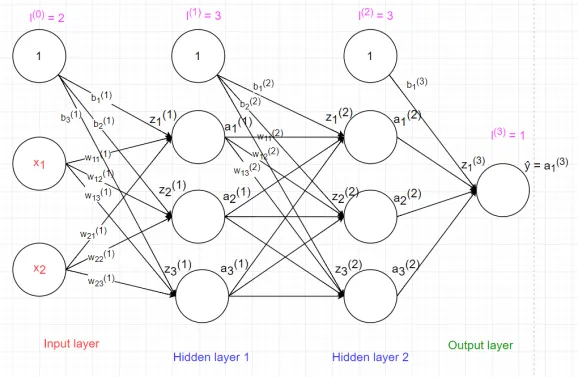
- Output của lớp trước là input của lớp sau, được tính thông qua những weights (đường nối)
- Quá trình train model ⇒ đưa dữ liệu liên tục để điều chỉnh lại những tham số (weights)
- Kết hợp với Big Data cho ra một model chính xác
Keras là gì
- Là một thư viện high-level so với phần low-level (backend) là TensorFlow
- Cú pháp đơn giản hơn TensorFlow
- Có thể chạy trên cả CPU và GPU (ưu tiên GPU)
Các khái niệm cơ bản trong Keras
- Sequential
- Là một khái niệm miêu tả thực thể chứa các layers trong Keras
- Layers
- Dense
- Conv2D
- Flatten
- Activation Function (hàm kích hoạt)
- Mỗi lớp trong Keras có hàm kích hoạt khác nhau ⇒ tùy bài toán sẽ chọn hàm kích hoạt cho phù hợp
- Fit: train model, fit data vào trong mạng neural
- Loss: hàm mất mát ⇒ điều chỉnh weight sao cho mất mát là ít nhất
- Optimizer: Giúp tối ưu thuật toán (Adam, SDG,…)
- Evaluation: đánh giá model
Các bước xây dựng Neural Network đơn giản bằng Keras
- Bài toán ví dụ: dự đoán tiểu đường dựa vào dữ liệu Pima Indians Diabetes Database ⇒ xác định những thành phần quan trọng của 1 bài toán
- Input: Thông số của bệnh nhân (Nguồn: https://gist.github.com/ktisha/c21e73a1bd1700294ef790c56c8aec1f)
- Output: Dự đoán bệnh nhân có bị tiểu đường hay không? (Type: Có hoặc không)
- Nhận định và xử lý data:

Data ta có được là 1 chuỗi số bao gồm những thông số của bệnh nhân như số lần mang thai, nồng độ glucose, v.v… và giá trị cuối cùng là 0 và 1 tương đương với không mắc và mắc tiểu đường.
Các bước xử lý 1 bài toán NN:
- Load dữ liệu → xây dựng model (xác định số layers, mỗi unit trong 1 layer) → compile model (gán hàm loss, gán hàm optimize…) → train model → đánh giá model (loss, accuracy…) → dự đoán dữ liệu mới → lưu model → load model
- Load dữ liệu
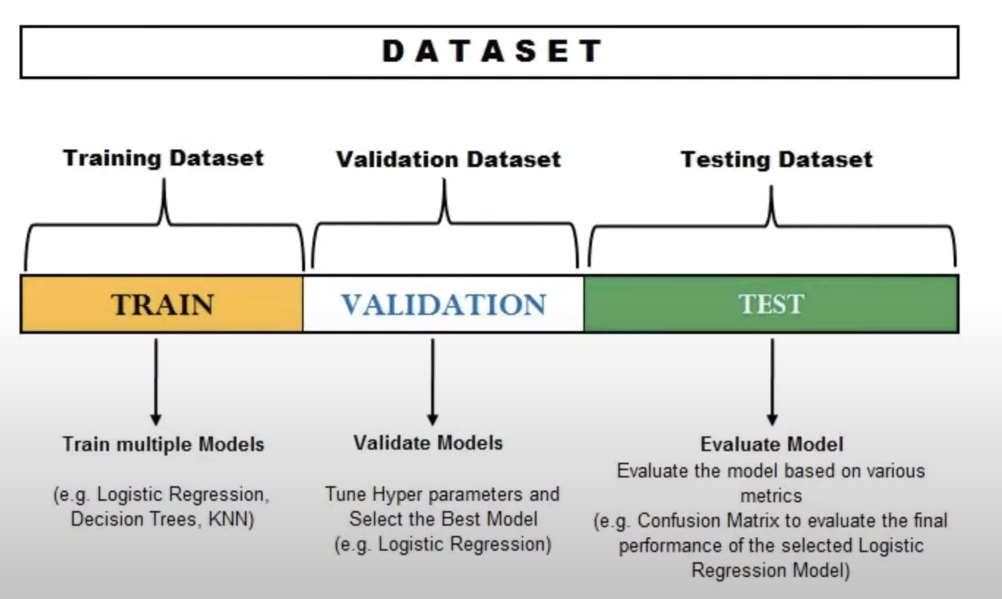
- Chia dữ liệu ra làm 3 tập chính:
- Train: Dùng để fit dữ liệu vào trong mạng và tối ưu các weights
- Validation: Kiểm tra tính tối ưu model → chỉnh sửa tham số để cho ra model có validation score tốt nhất
- Test: Đánh giá model → độ chính xác của model
Bắt đầu thực hành với bài toán Deep Learning
Cài các thư viện Python:
- Sử dụng PIP (TensorFlow, Keras, NumPy, Scikit-learn)
Load dữ liệu và chia Val và Test
from numpy import loadtxt
dataset = loadtxt('pima-idians-diabetes.data.csv', delimiter=',')
- Import thư viện numpy
- Đọc dữ liệu từ file text vào ma trận dataset
X = dataset[:,0:8]
y = dataset[:,8]
- Input (X) là các giá trị từ 0 đến 7 trong ma trận dataset (thông số sức khỏe)
- Output (y) là giá trị thứ 8 trong ma trận dataset (có bị tiểu đường hay không)
from sklearn.model_selection import train_test_split
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.2)
- Chia giá trị train và val chiếm 80% và giá trị test 20% (tham số test_size=0.2)
- Chia giá trị train của X và y là 80% và giá trị val là 20%
Xây dựng model
- Ý tưởng:
- Lớp input bao gồm 8 units
- Lớp output bao gồm 1 unit
- 2 layers: L1 gồm 16 units, L2 gồm 8 units
from keras import Senquential
from keras.layers import Dense
model = Senquential()
model.add(Dense(16, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
- Tham số trong lớp Dense:
- 16, 8, 1 → số unit trong lớp
- input_dim=8 → số tham số input cho 1 bản ghi
- activation=’relu’ → hàm kích hoạt relu (phi khử tuyến tính)
- activation=’sigmoid’ → hàm kích hoạt sigmoid (hàm đồ thị chặn cho phép chúng ta xác định tính chất dựa trên khoảng giá trị nhất định), hình ví dụ:
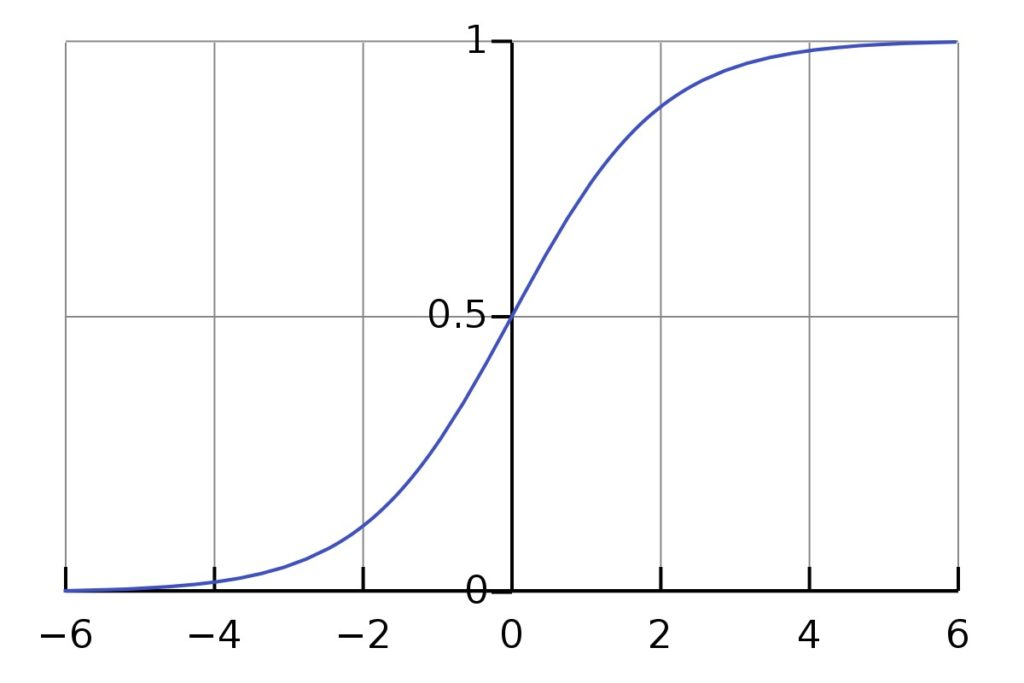
Summary Model (optional)
model.summary()
- Giúp chúng ta có cái nhìn tổng quan về model → có thể chỉnh sửa lại các tham số sao cho hợp lý
Compile Model
- 3 hàm chính: Loss, Optimizer, Metrics
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
Train Model
- 3 tham số chính: Epoch (số vòng train), Batch_size (số phần tử được lựa chọn để fit vào model), Validation
model.fit(X_train, y_train, epochs=100, batch_size=8, validation_data=(X_val , y_val))
Tips: tham số epochs và batch_size chúng ta nên thử từ nhỏ đến lớn để đánh giá độ tối ưu của model.
Đánh giá model
loss, acc = model.evaluate(X_test, y_test)
print("Loss = ", loss)
print("Accuracy = ", acc)
- Một số vấn đề cần chú ý khi đánh giá model:
- Các thông số Hyperparameters (siêu thông số): epochs, batch_size
- Chia data phải đảm bảo các class phân phối đều nhau
- Accuracy không tăng sau các quá trình train (data overfit vào dữ liệu train → không thể tối ưu thêm)
- Accuracy quá khác biệt giữa tập train và tập test
- Check point để lưu model
Dự đoán model
- Dùng 1 tập giá trị ngẫu nhiên để dự đoán tính chính xác của model
import numpy
X_new = X_test[10]
y_new = y_test[10]
X_new = numpy.expand_dims(X_new, axis=0)
y_predict = model.predict(X_new)
result = "Tieu duong (1)"
if y_predict <= 0.5
result = "Khong tieu duong (0)"
print("Ket qua du doan = ", result)
print("Gia tri du doan", y_predict)
print("Gia tri dung = ", y_new)
- X_new là giá trị X_test thứ 10, y_new là giá trị y_test thứ 10
- numpy.expand_dims: thêm chiều cho mảng để có thể chạy với TensorFlow
- Nếu giá trị dự đoán và giá trị đúng gần nhau ta in ra kết quả dự đoán
Lưu model để sử dụng cho các lần sau
model.save("examplemodel.h5")
Load model
from keras.models import load_model
model = load_model("examplemodel.h5")